
Update dependencies#
Why update software dependencies? Don’t forget that even docker has a dependency on the operating system (typically Linux), and the operating system depends on the existence of the computer hardware (e.g. x86), and the hardware exists because it depends on people who manufactured it and put it there. A dependency chain has no base case, except perhaps the big bang. The deeper you go the more stable dependencies tend to get (the length of time they have been pinned) though this is not a guaranteed or reliable rule (no matter how deep a dependency, it can be replaced with a newer dependency that provides equivalent features).
This is not merely an abstract notion. At map-making companies, you’ll depend on LIDAR scanners, cameras, an IMU, and various other small pieces of digital hardware. On top of that, you’ll be dependent on business processes that keeps cars running and driving in the appropriate locations.
These other dependencies can easily break your software in an irrecoverable way (though not if it’s built in a maintainable manner). Computer desktop hardware is probably pinned for 5-8 years (unless you e.g. install more RAM, which won’t break anything). Your operating system is probably only pinned for a few weeks at a time, until you run sudo apt upgrade. You don’t pin system packages because you often need your system for many other tasks besides some single application. Consider all dependencies, including humans, businesses, and hardware. Software may depend on an operating system, a docker image, system-installed packages, manually-installed binaries, user-installed packages, conda packages, pip packages, and shell scripts. That is, try to look beyond the first tier of your Supply chain:

The major advantage of libraries is that you do not need to write them yourself, effectively reinventing the wheel. Reading library code is often more enjoyable than reading your own or your team’s code, because you know it is more generally useful outside the context of your current job or project.
For all the same reasons, you probably want to upgrade regularly so you can work with the same open source (more general) software out there on the internet. Going through an upgrade of your dependencies often gives you an opportunity to learn about what is happening in the outside world rather than chasing after your project’s idiosyncratic needs. Said another way, taking the initial dependency on a library is often the smallest step in a relationship. If a library is available, how much of the API you use should expand and contract as your trust relationship with it changes.
More than ever, the software you need to perform a task is being created quickly in an open domain on the internet. This is driven not only by an increasing number of software developers, but by the simple fact that there has been more time for consumers to replace proprietary with open source dependencies. Software developers should spend more and more time evaluating libraries and incorporating them than writing their own version, assuming this trend continues.
Sitting on the old side of a library’s stable version means you’ll always be looking up the old documentation online, because you know the “stable” version may be different than what you’re using (see e.g. PyTorch 1.3.1). It’s often only through accidentally reading the stable documentation on a project that we discover there are features we want from it.
🔫 Trigger#
An upgrade is often triggered by the desire for an upgrade in a single library or package, even if in the end it is often necessary to update a set of libraries at a time to find a new working combination of dependencies. Alternatively, you can adopt a policy of regular updates that ensures you have the latest version of a library before you need it (if you have a strong trust relationship with certain libraries). We’ll compare these two options in more detail after introducing a few concepts.
Stability#
We’ll use the term “stable” in this article to mean the fraction of automatic and manual tests we expect to pass for our particular top-level application (or library). Notice the article Stability makes it clear this term can be used in many different ways; in Memoize artifact we use a slightly different definition. Critically, we include “manual” tests or tests executed by a human with typical assumptions about our domain. We often can’t afford to run all these manual tests before a release because properly educated humans can be expensive.
We could expand this definition to mean “stability” for a given dependency configuration, or the sum of the fraction we expect to pass across a range of dependency configurations. Usually this is a belief statement, that is, a prior given what we know about a particular library. It may depend on our past experience with the library.
The word “compatible” is arguably appropriate as well; see Backward compatibility. A library can be “stable” or “compatible” with respect to many others not only in the direct sense but in the sense of having dependencies on the same libraries that other libraries depend on (so that they can be installed in the same environment). To be “stable” implies might also imply that the library has a history of being compatible (and therefore will likely be compatible in the future) or even has made a formal promise to remain stable (e.g. for 5 years of support).
📛 Names#
What are we updating when we update dependencies? Every library you depend on has a name, and that’s in some sense the first and most important part of a version name. Saying you depend on libboost-chrono or Boost.Chrono is a “conceptual” statement; the meaning of this word can change over time. This is similar to how the English language is changing and many LLMs go quickly out-of-date regarding what a word means. As an example, many people depend on vi conceptually but then jumped to a vim or nvim dependency. These words are “synonyms” to only a limited degree; in general many words we call synonyms are only roughly so. Per Synonym, with emphasis added:
Don’t forget that names are more important than version names. In docker, users are always going to start with your :latest image (essentially no version name). In python, users are always going to try to install your package without a version number before getting to that second level of detail. These packages should not be equivalent to where HEAD is pointing (or main) unless you’re confident that your users are as invested in the product as you are.
Version names#
When we pin a version name or number, we’re being more specific about what we mean and removing some set of closely-related synonyms. This is often more necessary in “production” environments, where we want to be careful about we say so that it can be taken unambiguously for a longer period. Our production users are the least invested in our product and aren’t interested in understanding the ins and outs of it it something breaks (they also don’t already understand the ins and outs, to make a decision about whether something is wrong or right). They want predictable results, that others have already vetted. If something breaks, they’ll try a different dependency than ours (start a different relationship).
Many versioning logics let us talk in increasingly ambiguous manners about a dependency. In Semantic Versioning we can pin from zero to three digits, decreasing ambiguity as we pin more digits about what we mean. Most versioning systems define a “bottom” or most detailed version type, where the user essentially says they will accept no change in the package (equivalent to downloading and archiving an artifact).
Neither high or low ambiguity is necessarily the best. For example, most of the time you should upgrade dependencies that relate to security immediately, meaning you want to leave the last digit of the names in many versioning logics unpinned. One exception might be production environments that aren’t exposed to users outside your company or team.
To specify various kinds of packages, see:
The most invested users (developers, testers, your CI/CD systems) will generally be less specific in their pinning. By not pinning, these users make it more likely that they’ll discover some issue that would have otherwise made it into production.
The process of tagging is giving something that doesn’t have a specific name (perhaps not even a version number) a more specific name. This is almost always done with an intention to test in another more production-like environment, so it almost always corresponds with a release. Keeping these activities together also helps avoid spamming your namespace.
We need “manual” deployment steps because only humans are tracking risk and trading off the benefit of something working vs. the risk of it failing. When there’s risk involved, we want to have a human (or a team) involved who has the most advanced understanding of the tradeoffs involved in releasing vs. holding off. Teams often make this decision together because we don’t want others taking risks that we will have to pay for if the risk doesn’t pay off. It’s when we’re thinking of what “others” might do that we create systems that allow for separating their work onto branches. If we were the only ones around, we’d be happy to keep it all on master.
❤️🔥 Desiderata#
What would we like in a versioning system? Are there any requirements that any system must have?
🗿 Immutability#
See Semantic Versioning § 3. Many developers start by specifying a dependency in a completely ambiguous way (e.g. not even stating a version number). When they run into problems, they then swing to the other extreme and want the ability to be completely unambiguous, to the point where they can essentially specify a filename (and if necessary, can check the md5 of the file never changes). Although neither extreme is usually correct, having this extreme available is usually desirable.
This includes that names don’t stop referring to anything, because the file backing the name was removed. In docker container registries, having at least one name assigned to every image ensures none are ever lost. If names can’t ever stop referring to an artifact (file), then we clearly need to think about lifecycle planning of artifacts that are large (think docker again, where images are often easily GBs each). Even if a “user” never touches any of these old versions, having old build artifacts around is potentially useful for developers if they need to debug when issues were introduced (although it comes with a storage cost).
🩲 Short names#
Version names should (ideally) be brief. The minimal advantage of a version number is to provide a coarser and more memorable name for a version of software than the SHA that is defined by version control. Since we’re often manually typing out these names (in particular, when pinning), it helps if they’re short enough to remember. That is, try to hit something near The Magical Number Seven, Plus or Minus Two.
At the minimum this means users can download separate versions of the software and have the files already not conflict in terms of the name (think of how files in a Downloads directory are often auto-incremented if a file of the same name already exists).
There’s clearly a conflict between a name being immutable as well as short. A version naming logic that assigns extremely short names (i.e. integers) to files is clearly at a high risk of accidentally assigning the same name to two different files, which is disallowed by the immutability requirement. The smaller a namespace, the more likely a selection from it conflicts with a previous selection.
One way that a name can change from meaning one thing to another (after some time) in an intentional way, in an effort to help the user by e.g. fixing some issue and still letting them refer to the same name. Another way for this to happen is that our name-assigning system accidentally creates a namespace conflict because we e.g. reuse the same name twice in a row (clobber something we just published, which at worst is running in production for others) or reuse the same name months or years later due to our namespace being too small. See also Software versioning § Resetting.
The two most common ways to achieve this are to centralize the name-generating source (think SVN or GitLab build numbers) or give up on short names (think of git SHA). Obviously, neither of these solutions is ideal.
➡️ Order#
As discussed in Software versioning, a variety of version numbering systems are possible. Most (but not all) provide at minimum a total order on revisions of a software. As discussed in Software versioning § Software examples, this order can be quite original to the software. This could be nearly any sequence in theory: the integers, real numbers, latin alphabet, greek alphabet, etc.
Assigning an order to version names almost surely requires centralization of the name-generating source. Creating a simple source file with the version number (think a plain text file with 1.2.3 in it) in git will almost surely lead to merge conflicts when multiple developers change it for their own branches (or their own forks). The typical solutions to this problem are to adopt business processes (human coordination, such as incrementing the number only after or before releases) or have centralized computers in e.g. CI/CD auto-increment version numbers at certain checkpoints.
With the adoption of ordered version names, centralization is inevitable. In fact, ordered version names can be seen as a method to bring a team together. They can even be seen as authoritarian; it’s no longer possible for different developers to have different opinions about how the software should work on e.g. their own forks. The solutions suggested in How do you achieve a numeric versioning scheme with Git? (and A successful Git branching model » nvie.com) ultimately hide that ordered version numbers require developers to either release faster (a kind of centralization or authoritarianism) or fork with a new name when their opinions differ on what their users should adopt next (i.e. what the next version name should be).
⌚ Map to Time#
A direct or indirect map to time may help users decide whether a package is likely to function with their software today; all software rusts and much will not continue to function without regular updates. If no one has touched a particular piece of software in years, it’s also possible (even if the code still works) that it won’t receive updates when they are necessary. Untouched software is also not receiving features (arguably acceptable). A date won’t solve defects, but users are often interested in them because they are so easy to understand.
Version numbers (in contrast to SHA or version names or branch names) assume the advancement of time corresponds to “progress” in some way and that this progress is linear and controlled by a single individual or organization. Version numbers don’t allow for software forks (unless the base name also changes) or even long-lived branches. This centralization can be seen as an advantage; long-lived branches represent work that should be released.
Numbers and this implication of progress also imply (without requiring) that features are never removed. As discussed in Software maintenance, this often means that software must eventually be retired. Although it’s possible to remove features through a deprecation process, more often users assume that later versions include the features and bug fixes of earlier versions. Long-lived software is more of a relationship between consumers and producers, and a deprecation process needs to be a part of it from the beginning. Said another way, sometimes major versions need to increase.
◀️ Backports#
A versioning logic doesn’t allow for the release of any branches until the introduction of at least one separator (typically a period) to delineate the parts of the version name (see also Software versioning § Separating sequences). Although without proper maintenance these branches will look like a partial order in your version control system (e.g. git), the version numbers associated with them will still define a total order. See Semantic Versioning § 11 for an example of a relatively complicated total order, and Software versioning § Version number ordering systems for examples of tricky systems.
There may be multiple branches in git for different major versions, but the latest version of 2 should be mergeable into 3 (often this must be a no-op merge). In this way, we should be able to make our version control system reflect the linear order of our version numbers.
The addition of separators means there will be no clear relationship from versions to time (⌚). Even if we can be confident that 2.0 < 3.0 with respect to time, it’s possible that 2.1 was released either before or after 3.0.
This feature should be seen more as an expansion of the version logic from the natural numbers to the real numbers (see also Software versioning § Incrementing sequences). Between any two real numbers there are an infinite number of numbers, even more than the natural numbers. By introducing separators, we let ourselves go back to older versions and release updates to them with less change (and therefore risk) to our customers.
📏 Change measurement#
Users are interested in how much software change is associated with every version name change, sometimes because they are interested in features (how much they’re going to get from upgrading) but more often because they are interested in risk (what might go wrong if they upgrade). See also Software versioning § In technical support and Software versioning § Change significance.
There is obviously huge opportunity in a buyer-seller relationship for deception at this level (as discussed in Software versioning § Version numbers as marketing). A version number that is nothing but a date doesn’t indicate whether any developers were working on software in the last year or not; this is actually preferred by companies trying to sell software to continue to pull in revenue for old products that are being minimally invested in by making pretending more is happening in the product than actually is. Even version numbers that aren’t dates may be forced forward to indicate progress.
Other times a “developer” wants to pretend there’s less change than there was. If you’re releasing a document to someone indicating what you want, you often don’t want to show how invested you are in your plan (which would indicate to them they can charge more).
It can be difficult to get other teams in large companies to accept upgrades of e.g. the OS or any dependency that is direct to your team but transitive with respect to them (if e.g. they are in maintenance mode and only want to get features by updating a number). If you don’t include as many version number increments in your changes (e.g. don’t increment a major or minor version number) then they’ll more naively commit to an upgrade.
Does this feel like statistics? Consumers of a library don’t know what actually changed semantically, so they treat version numbers like data that indicate what is usable and what isn’t (probabilistically). Producers know this and try to do what they can to keep their user abstracted (dependent) and interested (There are three kinds of lies: lies, damned lies, and statistics).
In fact, you see a version number with lots of separators as a row in a table of values specific to your project. That is, semantic versioning and similar systems provide something like a row in a dataset. Some systems (not semantic versioning) separate the columns of the row with the same character (a -) for consistency. If you’re using ISO 8601 dates this usually implies dropping the dashes from the start of this string to ease parsability.
Said another way, version numbers are essentially a way to communicate a history to someone who isn’t interested in the meaning of each version (an artificial history). When you learn e.g. the history of mathematics or any other real history you are forced to tie dates to concepts (when the concept was introduced). This extra map is extra work.
When you’re updating version numbers ask yourself whether it’s easier to actually read the source code or continue to learn the idiosyncrasies of a library that you clearly need.
📜 Artifact names#
Packaging of software is complicated, and developers often need to provide the same source code in multiple forms or rebuilt in “insignificant” ways. In CI/CD systems, it’s common for the same software to be rebuilt first as part of an initial release and then later if someone hits a “rebuild” button simply to check if the build or release system is still functioning. If this results in a second release of a package, then you’ll end up with two packages that are theoretically equivalent (not a single line of code changed) but that may not be equivalent if you don’t have a hermetic build. Since docker builds are not hermetic, this is a common problem. If you want your version numbers to be immutable (🗿), then they essentially need to extend to being artifact names because of this risk.
In this scenario, the build metadata is being saved exactly because dependencies could have changed. The “right” solution to a non-hermetic build is to make it hermetic. Depending on the artifact being produced, however, it’s likely that when the artifact is deployed it will use the dependencies in the system it is installed in so that changing dependencies in the builder docker image are not relevant.
Other times, the same software needs to be released with a different dependencies. For example, you may be releasing your software built under both Ubuntu 22.04 and 24.04 (e.g. a docker image based on each of these Ubuntu versions) and your users are almost surely going to be interested in this distinction to decide which version they pull. Many packages are built for both python2 and python3. You may want to distribute both a debug and release version of your software (with the former including debugging symbols).
As an example of how this might be specified, see Semantic Versioning § 10. In this example, with the introduction of artifact names our versioning logic gets back to defining a partial order, but not one that will be reflected in version control (unless artifacts are also stored in git).
The term “artifact name” can also be defined in contrast to “version name” where we let an artifact name be much longer (including SHA or dates, so that it’s easily immutable) and a version name sit at the base of an artifact name (so it can stay short and memorable). With this definition of the terms, we would encourage users to adopt version names (to allow us to do servicing) but still give them the option to pin to long artifact names. Another way to distinguish these concepts are to refer to a “full” version number and a partial version number (1.2.3 is fuller than 1.2).
📅 Pre-release versions#
See Software versioning § Pre-release versions and Software versioning § Designating development stage. It’s rare for a complicated package to have automatic tests that are so thorough that the development team feels it can be released without any manual user testing (especially when there are user interfaces that are hard to automatically test except via e.g. mouse moving software or AutoHotkey). To sanity check the release, this kind of software typically requires some time with users.
See Semantic Versioning § 9 for an example of this feature in a versioning logic. Notice that semantic versioning includes alpha and beta in their example because they sort lexicographically. They can’t continue because the next (traditional) release version would be gamma (which would lexicographically come after delta, the fourth greek letter). Although greek letters are used in the traditional software release life cycle, you may want to drop the greek letters with this system and simply use the latin alphabet for stages of testing.
Versioning logics#
Version SHA (🗿)#
The git SHA out of your version control system is a good version name for those who are already highly invested in a project. These people will typically have the source code available and can check out the git log to understand what a particular SHA includes.
Release notes and changelogs are essentially a compression of a git log, something that anyone who is more invested in a software product can get automatically. Customers often demand something “more than” the git log in release notes, which is something they are not.
If everyone was equally invested, the goal would be to eventually remove all version numbers (creating a monorepo or multirepo). In that scenario, you simply use SHA to point to git submodules rather than maintain version numbers. From this perspective, version numbers make less sense in a company where everyone should be on the same team. In this context, version numbers are used to assign blame.
In this sense, version numbers are unnecessary overhead. Despite being an additional cost, however, they come with benefits. A SHA does not have many of the desirable features mentioned above (🩲, ➡️, ⌚, ◀️, 📏, 📜, 📅). It also provides a layer of abstraction; it’s not possible for everyone to understand everything.
A major benefit of including the SHA in the artifact name is being able to quickly work back to the build associated with the artifact. This is fine, but this data can actually be included inside the artifact in many cases (in a docker image, as a file in the image). The same can be said of a date. For something like a PDF, you lose the artifact name when you print out. In that particular case, you can include the whole artifact name somewhere in the file (as is done when printing a webpage in the footer, automatically).
Version dates (🗿, ➡️, ⌚, 📏)#
If your version names are dates, then you’re almost surely going to need to embed dates into filenames. For suggestions on how to do this, see:
If you want immutability (🗿) then version numbers of this kind will not be brief (🩲) (even getting down to the second may not be enough, if you’re pessimistic or have many build machines).
However, see some of the examples in Software versioning § Date of release; clearly 18.04 is succinct enough. It’s possible to accomplish something like this by asking users to refer to a version software by when it was “initially” released, meaning that they refer to it by a version name rather than an artifact name.
Whether dates should be UTC or not depend entirely on your application. If all your users and all your developers are in one time zone and always will be, then UTC is a burden (it will only require everyone to do mental addition/subtraction). Timezones should always be specified in the ISO 8601 style, however.
Version numbers (🩲, ➡️, ⌚, 📏)#
In this article, when we say version number we’ll think of the natural numbers. In this particular section, we’re thinking of the version numbers that are a bare integer. These may be manually incremented or from a build system (a build number).
Dot-separated digits (🗿, 🩲, ➡️, ◀️, 📏)#
Version names of the form x.y.z where each of the three variables are integers.
Although SemVer provides one possible interpretation of these three digits, if you’re versioning something other than software with a public API then you’ll have your own interpretation of every digit. For example, imagine you were providing versions on a PDF you distribute to others. You may want to increment the major version for chapter rearrangements, the minor version for paragraph rearrangements, and the patch version for typos or fixing broken links.
SemVer (🗿, 🩲, ➡️, ◀️, ⌚, 📏, 📜, 📅)#
Semantic Versioning is essentially the answer “all of the above” in the sense that this system lets you includes dates, SHA, and whatever else you want as long as you stick to numbers as the base system.
Most of the parts of a version name are manually-generated (or at least manually incremented) by a human. Notice semantic versioning puts the most valuable information (i.e. 1.2.4) first i.e. the information not only generated by a human but compressed into integers. After that you see what is often a manually-generated branch name (the “pre-release version”), and after that what is likely a computer-generated SHA or date (the “build metadata”).
Although this system attempts to assign a meaning to three integers, there’s no guarantee that the developers producing the software are correct when they increment or choose not to increment them. In this sense, these numbers are still probabilistic but are produced by an expert human source. The article Software versioning § Semantic versioning describes each number in terms of decreasing risk.
Notice Semantic Versioning 2.0.0 § Backus–Naur Form Grammar for Valid SemVer Versions was removed from Semantic Versioning 2.0.0-rc.1. This grammar appears to have included redundancies, based on a brief look.
Dual systems (🗿, 🩲, ➡️, ◀️, 📏, 📜, 📅)#
The article Best practices for tagging and versioning docker images – Steve Lasker argues for a system of this kind where “stable” tags correspond to version names (short and memorable i.e. 🩲) while “unique” tags refer to artifact names (immutable i.e. 🗿).
In this particular system, there are actually two versioning logics running alongside each other. Humans maintain the stable tags (with SemVer), and a centralized computer maintains the unique tags (an integer version number corresponding to a build ID). In almost all git projects you’ll see a similar approach where the annotated tags in the repository are maintained (i.e. manually picked) by humans:
You can then use git describe to come up with names for your artifacts. Separating the name use for artifacts from the release number managed by humans is critical to avoid humans incrementing the wrong version number in the interest of retaining namespace. If you’re pushing a change that may not work for downstream consumers (e.g. a toolchain image or external library package) it’s tempting to increment the first of the three version numbers (e.g. 3.0.0 to 4.0.0) only because this leaves you space to try two other experiments with 3.1.0 and 3.0.1 if the first fails. It may be appropriate in this situation to always increment the first number because the package is so extensive, but it shouldn’t be a requirement.
Another common example of a dual system is where marketing and engineering maintain their own versioning logics. See Software versioning § Internal version numbers.
Manual version increments#
If there’s a human-managed version number, do you increment it at the start or end of a development cycle? You could release version 1.2.0 and immediately change it to 1.3.0 so that 1.3.0-sha indicates you are providing a prelease version of 1.3.0. Or you could continue to label all your commits as 1.2.0-sha so that the addition of a SHA indicates you are providing some post-release version.
See Specifying Your Project’s Version - setuptools for a standard allowing you to explicitly specify either post-release or pre-release. Semantic Versioning unfortunately only allows pre-release, but build metadata effectively allows post-release. With git-describe, you can only get post-release. Whether you choose post-release or pre-release, be explicit when possible.
The major problem with prelease versioning is that you need to know what you’re going to release next. Are you going to work on a defect (increment the last number) or break the API (increment the first number)? Unless you have a plan in place and no other developer has plans to make some other change on master, then this is a hard decision. If you’re committed to releasing on a regular cadence, as is best practice, then you can’t be sure that you’ll even get both features and bug fixes released.
In some systems, you literally start a fork for the major, minor, and patch versions (development and maintenance branches). This is common if e.g. some customers are only paying for maintenance and some are paying for a new version. The major downside to this approach is that if features and defects interact, you’re producing unnecessary work resolving conflicts. This way of thinking leads to the strongly opinionated answer in When do you change your major/minor/patch version number?.
Another argument for pre-release versioning is that it avoids accidental clobbering of already-released artifacts. If 2.0.0 was released but is still the tracked version number in a file in the repository, then someone could potentially clobber re-release an artifact over the old one. This can be avoided by always including build metadata in artifact names, and only creating a copy of an artifact with build metadata in the name when you do an official release. See Best practices for tagging and versioning docker images for how this is done with pointers in docker repositories.
The conflict between these two systems is similar to the conflict between giving branches meaningful names to start, or only when you’re ready to submit an MR. If you start with generic branch names then at the end of every day you can describe what you’ve done on the way to your goal in a new branch name and get constant feedback from other developers through the week. If you commit to a certain goal with your branch name, you may end up stuck on a branch until your work is complete. Both version numbers and branch names are a compression (summary) of all the work done since the last version number change or the start of the branch. With a version number, we compress the work down to only a few standardized digits.
🔫 Upgrade!#
Let’s say a team of maintainers of Library A (including you) have avoided all dependencies (excluding the standard libraries). They hear about some Library B that does something they are already doing. The other library has some great ideas and is essentially doing what the team is already doing in a better way. Said another way, they are going in the wrong direction with their own code. They decide it’s OK to take this whole library as a dependency and refactor the code to depend on Library B.
As a library maintainer you know that you can’t test everything. You have many users, sometimes with unique needs, and they aren’t sharing all their tests with you. Often tests are manual rather than automatic. It’s possible this other library’s automatic tests are known to be incomplete in important areas. Typically a “bleeding edge” release identifies where your package is unstable, but this is a fuzzy line. For an example of a bleeding edge, see When you should switch to Python 3.x.
Library B doesn’t explicitly indicate which versions are maintenance, stable, bleeding edge. etc. so you guess which version is the most stable. Let’s plot the mean of these priors, assuming a library with integer versions:
import matplotlib.pyplot as plt
import numpy as np
def stability_1d(versions, time_or_version):
return np.maximum(1 - np.abs((versions - time_or_version) / 4), 0)
def plot_1d_stability(versions, lib_stab):
fig, ax = plt.subplots(figsize=(10,10))
ax.stem(versions, lib_stab)
ax.set_xlim(-0.2, time_or_version + 1.2)
ax.set_xlabel("Library B")
ax.set_ylabel("Assumed Stability")
versions = np.arange(11)
time_or_version = 5
lib_stab = stability_1d(versions, time_or_version)
plot_1d_stability(versions, lib_stab)
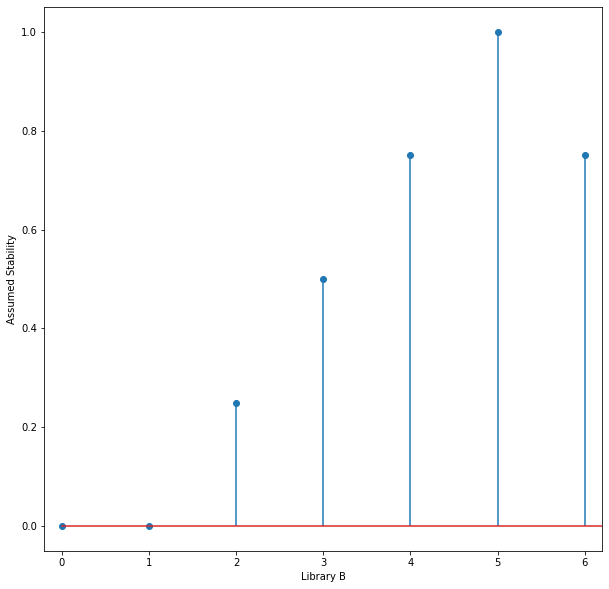
Not knowing which version was most stable based on release notes, you had to guess that the latest (version 6) was a bit less stable than version 5 because it was so recently released, and you’d be discovering the defects on it rather than relying on issues (which usually come with workarounds) that have already been reported on version 5. It’s possible that there are fewer users on version 4, though, and that it doesn’t support some newer libraries you’re using. You may not get any support if you report an issue with too old a version.
You refactor your code, making a version of Library A work with what you believe is presently the highest stability version of Library B (version 5). After your release, let’s say a user of your Library A were to ask how hard it would be to backport your refactor to an older version of your source code, perhaps to get a feature made possible by Library B on an older branch. They’re also curious how hard it would be to use a different version of Library B than the version 5 you suggest, in case a user already has an older or newer version installed (or needs a different version because of other library dependencies).
We’ll assume your own library also uses integer versions (and is also on version 6). In this plot, the alpha channel represents the fraction of your tests you believe would pass if you merged your changes to use Library B’s API, for various versions of Library A and B. This plot assumes a duck-typed language to some degree, where the whole build wouldn’t fail, but we could also see a compilation failure as a failure of all tests:
def stability_2d(versions, time_or_version):
lib_stab_b = stability_1d(versions, time_or_version)
lib_stab_a = stability_1d(versions, time_or_version + 1)
return np.maximum(lib_stab_b[:, np.newaxis] + lib_stab_a[np.newaxis, :] - 1, 0)
def plot_stability(libs_stab, time_or_version):
fig, ax = plt.subplots(figsize=(10,10))
version_a, version_b = np.meshgrid(versions, versions)
ax.scatter(version_a, version_b, alpha=libs_stab, color="black")
ax.set_xlim(-0.2, time_or_version + 1.2)
ax.set_ylim(-0.2, time_or_version + 1.2)
ax.set_xlabel("Library A")
ax.set_ylabel("Library B")
libs_stab = stability_2d(versions, time_or_version)
plot_stability(libs_stab, time_or_version)

Notice that consumers of Library A are limited in their upgrades to Library B (and therefore their upgrades in general) by how quickly Library A is updating its dependency on Library B, and how many versions of Library B it supports with every release.
There are (generally speaking) two update strategies going forward: when the need arises, or on a regular schedule. A package’s version numbers are essentially a suggested linear upgrade path for current users from a package’s developers, but it’s often necessary to stop at every point on it. If you’re on v22 it’s not even a hard rule that an incompatibility with e.g. v23 prevents you from jumping to v24, since the API change in v23 may have been reverted in v24 (after e.g. more discussions with users).
Patch release#
Let’s say the developers of Library A want to update their dependency on Library B, but it has been so long that the API has changed in every source file where they used the previous version of the library. Said another way, they have to do nearly as much work as they did to adopt the library in the first place.
time_or_version_v2 = time_or_version + 4
new_work = stability_2d(versions, time_or_version_v2)
libs_stab_v2 = np.maximum(libs_stab, new_work)
plot_stability(libs_stab_v2, time_or_version_v2)

Less net work#
This approach effectively creates stable islands that your users must jump between during upgrades. An advantage to this approach is that if there is a large space between islands you can avoid dealing with any back and forth that happened between the islands. Since you aren’t jumping on either the bleeding edge or even the stable release of your dependency, you don’t have to deal with any temporary defects happening on either of those channels. This approach is more analogous to moving to the house you want to live in rather than remodeling the one you’re already in.
As an example of this system, there are multiple versions of Ubuntu (22.04, 24.04) that users must jump between for upgrades, and less-stable islands between these islands (22.10, 23.04, 23.10). Unlike the situation described above, Canonical developers are constantly working on keeping the distribution stable between releases but only commit to keeping checkpoints that have been given more time (like 24.04) stable.
Need-driven#
If users were not actually consuming that features that Library B supported, then continually updating the library would be a waste of developer time. It can be hard to determine what customers are using in practice, and if keeping a library requires a relatively large amount of work then upgrading it only when the need arises (when a customer asks for it to be upgraded directly or indirectly) helps ensure it will only be upgraded if it’s needed by a customer.
More stable releases#
In general, this approach prefers stability and reproducibility to upgrades, and is therefore more common in a production environment. Any kind of software pin can be seen as a preference for stability to upgrades; to someone focused on getting upgrades done then pins need to be “fixed” but to someone focused on getting production to work pins are a feature.
By not constantly introducing new versions of software, we avoid the risk that our tests aren’t covering an issue. In general, this approach relies more on manual tests that are run in a regular way as part of releases; see Software release life cycle and Release management.
Once a particular version of software has been thoroughly manually tested, we don’t need to keep re-running those tests as we make minor bug fixes over the maintenance period of the software. Even if the software has automatic tests, those tests should not need to be significantly updated for the sake of minor bug fixes and security fixes.
Rolling release#
Another strategy is to simply stay on the latest or near the latest version of a library, even if you don’t immediately need the features provided by it. This creates a stable tunnel rather than islands:
import functools
def update_stab(libs_stab, time_or_version):
new_work = stability_2d(versions, time_or_version)
return np.maximum(libs_stab, new_work)
update_range = range(time_or_version, time_or_version + 4)
libs_stab_reg = functools.reduce(update_stab, update_range, libs_stab)
plot_stability(libs_stab_reg, time_or_version_v2)

More stable versions#
The most significant advantage of this approach is to be able to say you depend on a range of versions of a library rather than a single version. This is both the strength and the weakness; clearly there’s more work associated with this approach in the form of many more dark dots in the drawing above (making more software versions compatible, or checking and recording how they are compatible).
Some dependency stating systems do not have a way to say you can depend on e.g. v5 and v7 but not v6, but they do have a way to state you can depend on a range of versions. If you never have a release on v6 and instead only run your tests on it once, you may be missing issues it temporarily introduces.
Your users may complain you only support one version of the library at a time, rather than a range. If they depend on the same library, they’ll have to pin it to the exact same version that you use. Even if they don’t pin it at all but depend on another library that states a dependency on an incompatible version of the library you depend on, their dependency resolver isn’t going to be able to find a solution that includes your library. If you state you can support v6 but in practice didn’t get enough time testing on it, they’re going to file a defect when it doesn’t work.
Faster releases#
The patch release upgrade is necessarily a large (non-incremental) refactor because you can’t depend on two versions of a library at once. A major downside of non-incremental refactors is that the change is likely to conflict with other developer’s work on features in the library during the course of development. Any feature you plan to release based on your upgrade will also take longer to get out the door not only because the refactor took a long time, but because it was large and therefore also introduces more risk. That is, the release will stay in the “bleeding edge” stage for longer.
Eases upgrades#
Another major advantage to this approach is that it ensures upgrades happen, rather than software falling behind to the point of never being upgraded. When it takes focused work to make an upgrade happen, this also implies that a company or team will never build up the necessary level of commitment to do so. There’s often much more lower-hanging fruit (easier upgrades) than e.g. upgrading an OS like Ubuntu forward over two years of changes in the outside world. Taking a dependency on Ubuntu implies that upgrades must be given a focused attention at regular intervals.
A minor advantage to this approach is that because you likely don’t immediately need any features for the library you are upgrading, you can file an issue and leave time for the developers of your dependency to fix it before you upgrade. That is, check if the update is easy, and if it isn’t say something and go back to what you were doing. This involves jumping in and out of focused work on the upgrade process, but also avoids a panic to upgrade at any point.
Stable revenue#
The open source software community operates as a kind of gift economy, like academia. Library consumers pay in terms of performing updates and get paid in terms of features, and producers pay in terms of features and get paid in terms of popularity. For companies to monetize on the cost of software maintenance rather than only gain popularity (and try to monetize on that) they must ask users to somehow directly pay for it at some point.
Companies that follow patch release models (like Canonical) earn revenue on their software by creating a release, and expecting users who aren’t paying the cost of updating to eventually need to call to them for help in terms of extended security and maintenance (ESM) contracts. If customers overbuild (which is common) and don’t upgrade, then to support their own customers they’ll likely have to take this option. Per How Canonical makes money from Ubuntu | CIO this appears to be the primary driver of what makes Canonical profitable. Canonical has only been profitable since roughly 2018 despite being around since 2004 per Mark Shuttleworth on Ubuntu popularity and Canonical profitability | ZDNET.
For internal teams building software products in a large company, upgrades must always be provided alongside features to ensure that consuming teams “pay” in that sense. If the teams that are your customers can get features by doing nothing but upgrading a version number, they’ll scoff when updating that version number only includes risk to themselves because your team upgraded one of your own transitive dependencies without adding a feature. In some cases, they may ask you to backport the feature to a branch that doesn’t have any dependency upgrades they don’t want do (e.g. of the OS) (which then requires you to maintain the fork).
Change summaries#
It would have been better if you (as a maintainer of Library A) didn’t have to guess which versions of Library B were stable. If Library B had maintained release notes, then it would have been easier to say that e.g. v4 of the library was currently broken by simply checking these notes. In some sense, if issues filed against a project are public (as on GitLab and GitHub) then these can serve as release notes (indicating in particular broken versions and workarounds) if they are properly indexed by search engines with respect to the error messages that produce a problem.
For the sake of recording features and intentional bug fixes, a Changelog (a git log) is nearly equivalent to release notes, except perhaps in the sense of being overly detailed. The term “changelog” and “release notes” are often used interchangeably. Said another way, these resources allow developers to “theoretically” check whether they can upgrade without actually trying to do so experimentally. We put “theoretically” in scare quotes because it’s more often the case that you’re simply avoiding doing experimentation others have already done.
As an example of good release notes, see Changelog - pip documentation v23.0.1. Since certain versions of pip only support certain versions of python, it’s necessary to pin pip properly to get a working system during many upgrade efforts.
A mistake in a textbook is typically referred to as an erratum (see also Erratum). The distribution of a software package, similar to an already-published PDF, may contain errors that are not known at the time of the publication of the software (and therefore don’t make it into the release notes). If these issues are eventually fixed, then the “errata” associated with a software package is (to some degree) distributed across all the release notes for packages following the one in question. However, these follow-up release notes could also easily document defects introduced after the package in question was released. It is not common for package maintainers to record all the known issues with all released packages (something similar to an errata for every package).
Servicing#
See Best practices for tagging and versioning docker images – Steve Lasker for a definition of “servicing” an image. In the context of docker images, this essentially means keeping an up-to-date tag for the latest single-digit, two-digit, three-digit, etc. version numbers.
A version number can be seen as a lossy compression of all the bits that correspond to a file to some humanly-interpretable full version number. On top of this, there’s a monotone Galois connection (something similar to a floor function) between full version numbers and all kinds of partial version numbers.
There’s no reason that two full version numbers cannot effectively map to the same artifact. Developers could accidentally come back to the same API after experimenting with an API change that is publicly released. In this case, the 2.0.0 interface could refer to the same interface as the 4.0.0 interface and files in each series could even have the same md5. Version names are only an additional system on top of packages and many version naming systems can exist on top of the same series of artifacts.
💍 Lifecycle planning#
Nothing is forever. This in particular includes artifacts, and especially when they are large. If you’re generating 5 GB docker images as part of every build, and effectively saving them indefinitely by giving them full version numbers, you’ll quickly spend a lot of money on storage. Even if your artifacts aren’t taking a lot of space, you may generate so many files (spamming your namespace) that they are nearly impossible to look through. It’s helpful to have a list of releases for customers who aren’t keeping up with the bleeding edge.
There are at least two simple solutions to this problem: automatic and manual memory management. In an automatic system, you give full names to your artifacts and have some kind of garbage collector come by and clear out your e.g. docker container registry on a nightly or weekly basis, removing images that are older than e.g. one month and not used in production. This logic might be relatively complex to write, but early lifecycle planning is better than retrospective planning for a variety of reasons.
Without early lifecycle planning, you may find yourself with TB or PB of data with just a few select names used or previously used in production or in the field. How do you decide what to delete? It may be that 99% of it can be deleted, but you don’t know the 1% you really need to save. Creating huge docker images without having a plan to clean them up is like allocating memory and then passing around a reference to the memory without a plan to ever clean it up (leaking memory). Leaking memory is really much more forgivable, because it will always be recovered when the program stops.
If you had a process to delete images from the start, then when outsiders began to rely on your artifacts they’d have to go through the work of seeing it disappear in certain situations (according to whatever rules you laid down at the beginning). Otherwise, they’ll come after you when you start your cost-saving initiatives. They’ll say you should be saving “everything” forever, because that’s what you were doing for them before.
Alternatively, you can create “throwaway” or “contextual” names for build artifacts (e.g. based on the GitLab build number) and only give these artifacts “real” version names if you decide to manually promote them. This approach is effectively equivalent to manual memory management, but you can usually afford to leak memory because memory allocation takes manual development effort (and therefore little is allocated). The versioning logic you use for the “throwaway” names should be different than the one you use for “real” version names so that anyone using throwaway names cannot be the list bit surprised when their artifact disappears.
You can see this as names being something that humans remember, and how you need to have stages based on standard human memory from the beginning. Just like you first put artifacts in /tmp, then in ~, then in version control, different “kinds” of objects need to stay around for different durations. Production artifacts need to stay around for much longer than development artifacts, only because production needs to be supported much longer than development (think of LTS releases of Ubuntu). These things should be separated with a lifecycle that matches the promises made regarding support in production/SI/development.
Dependency Resolvers#
Whenever possible you should be using a dependency resolver rather than manual guess and check. See Dependency hell for examples of common tools.
It’ll help in the course of the manual work associated with an upgrade to be able to quickly see your dependency tree. Start with text-based solutions for both recursive and reverse dependency checks. See also:
Dependency Counts#
The number of additional packages you are installing naturally increases the risk you will fail to find a usable combination. It’s likely the decrease in stability is faster than linear, however. This is related to the Curse of dimensionality; there’s simply more “space” in larger dimensions so that individual samples represent a smaller fraction of the total. Imagine taking the 2-dimensional graphs above to three dimensions.
One of the first steps you should take when you run into an issue is to understand your dependencies
and delete as many as possible. It’s often easy to maintain a Linux installation on a machine for
years if you take time to delete dependencies when you run into a problem with apt.
If you can’t remove dependencies, an understanding of them can help you pin them less tightly. This gives your dependency resolver more “space” to find a working sample. See Loosen your top-level requirements.
Pin Dependencies#
Pin evenly#
Try to pin all packages, or none of them. Version numbers of course always increase together, with time. If you pin only one package and not another, one package may continue to get upgraded until it’s years apart from another (leading to failing tests). Even an existing stable “tunnel” between two packages won’t help with packages that have never been automatically or manually tested together.
Pin manually#
If you pin many packages, you have to manually update all your pins. Tools like pipenv and
conda-lock can help, but they often simply upgrade you to the latest version of every dependency.
If that configuration doesn’t work you have to manually edit your pinning, anyways. Still, these
tools can provide a starting point. These tools also can’t intelligently set dependency ranges, etc.
Pinning may include freezing external dependencies, such as the source you depend on in a .tar.gz
file. Saving these artifacts as files is manual work as well, work you must do every time you
upgrade them.
Generally speaking, the more reproducible your builds, the more work it is to upgrade them. You can take on this cost through repeated manual work or through setting up an automatic process. It’s likely best to do the manual work a few times until it becomes clear you’ll be doing the work indefinitely.
Copy-paste pinning#
To take a dependency on a library you can either install a package (with a pin) or copy and paste only the source code you need from the library. If you only need one or a few functions from a library, the latter solution may make more sense because you can avoid pulling in unnecessary dependencies the rest of the package uses.
You can see every source file in your repository as a dependency. These dependencies are effectively pinned; the pin is e.g. a git SHA. You can copy and paste whole libraries into your source tree as a way of pinning your dependency on them, for example if you want to:
Get some bleeding edge-feature, but not them all.
Include one bug fix but not another.
Use your own build system rather than the library maintainer’s build system.
Remove features that are causing dependency issues for you.
To copy and paste the source with modifications is to fork the project; you may want to let the library maintainers see your work. Your next upgrade will continue to be difficult in your changes never make it upstream.
Copy-paste pinning can be partially automated with a script that updates a git branch then copies across git branches.
Function-Level Dependencies#
It’s common to take a dependency on a library for one or two functions. If you don’t copy and paste in only the functions you need, stick to these functions you really care about rather than trying out random functions only because they’re available. If you do have an issue upgrading the dependency in the future, perhaps because it is incompatible with another library you use, you can change how you depend on fewer functions (e.g. by copying and pasting them in).
If you are writing a library yourself, stick to the part of your dependency’s API that you expect to change the least. In some cases, this may mean copying and pasting in new functions marked “alpha” from the library that only combine other features from the library. If you do have a user that depends on an older or newer version of the library than you’ve tested with, it will be more likely that your code will work with their version.